 Motivation: Visual Tokens are spatially redundant
Motivation: Visual Tokens are spatially redundant
Current large multimodal models utlize all visual tokens to represent an image. In LLaVA-1.5, all spatial (24×24=576) tokens are fed into the LLM, which leads to redundancy.
We propose a plug-and-play module to reduce the number of visual tokens, which can be conducted via either training-free or finetuning manner.
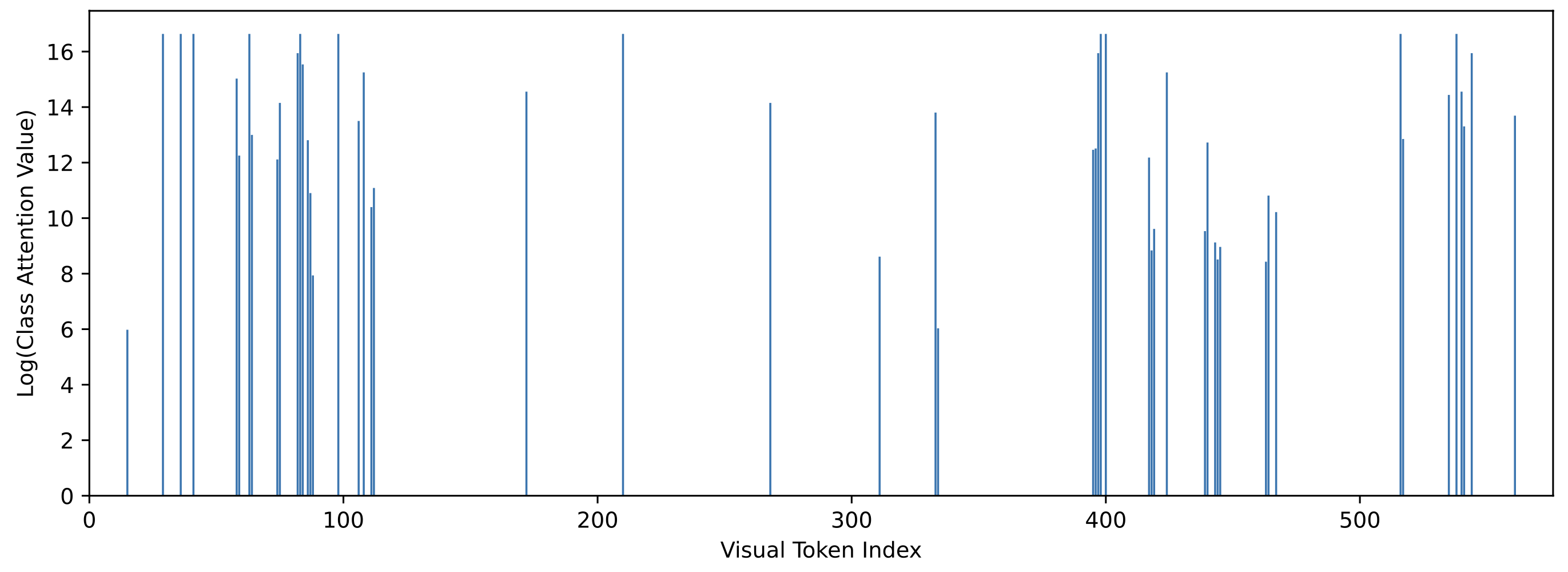
Interestly, we oberserve that the activations between the class tokens and spatial tokens in CLIP are very sparse, which can be leveraged to prune the visual tokens.
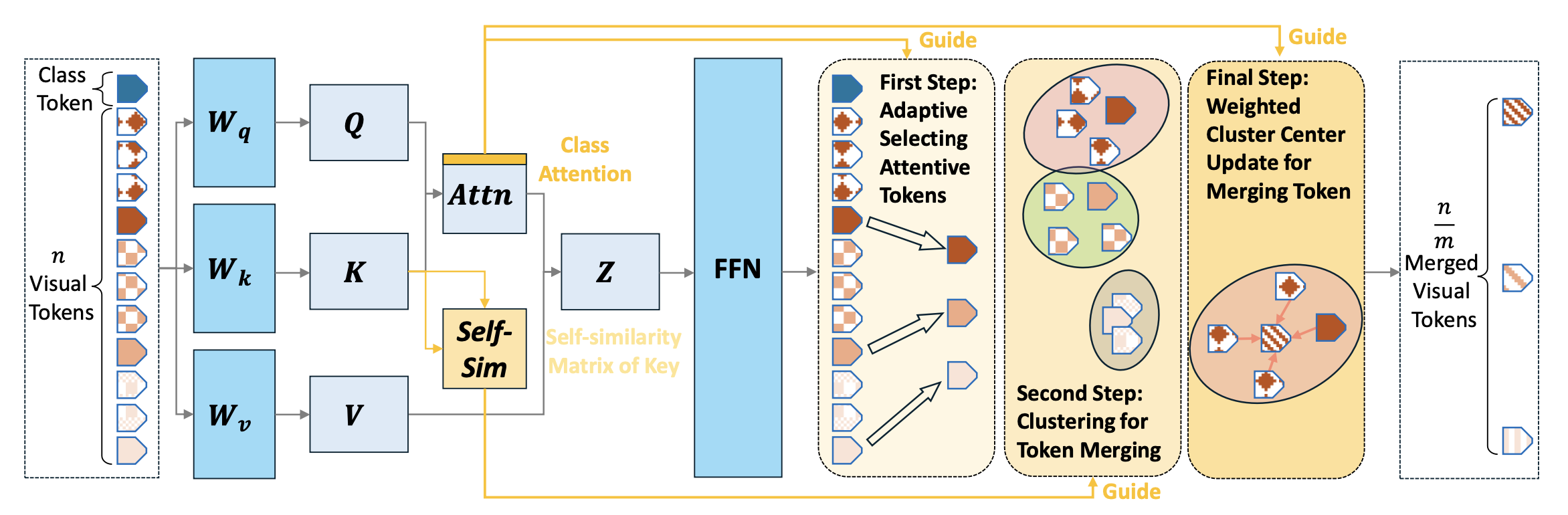
 The conceptual idea of LLaVA-PruMerge
The conceptual idea of LLaVA-PruMerge
Our approach has 3 steps:
- Sample important tokens according to the similarities between the class tokens and spatial visual tokens;
- Cluster the visual tokens via k-nearest neighbor;
- Adjust the sampled visual tokens via weighted averaging for each cluster. Here m denotes the visual token compression ratio.
Our sampled tokens can better reflect the key information in the image.

We can further ehanace the performance by supplementing with spatial tokens.

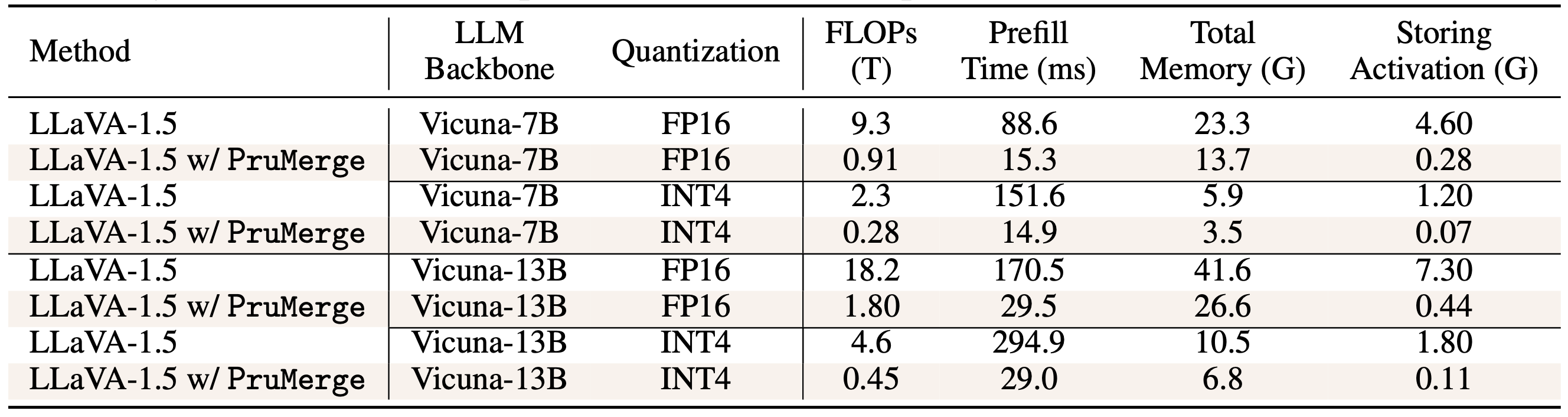
 Computation Cost Analysis
Computation Cost Analysis
Our approach can significantly reduce the computation cost. We evaluate on TESLA V100 GPU, and time estimated by the roofline model represents the theoretical performance that the hardware can achieve.
 Performance
Performance
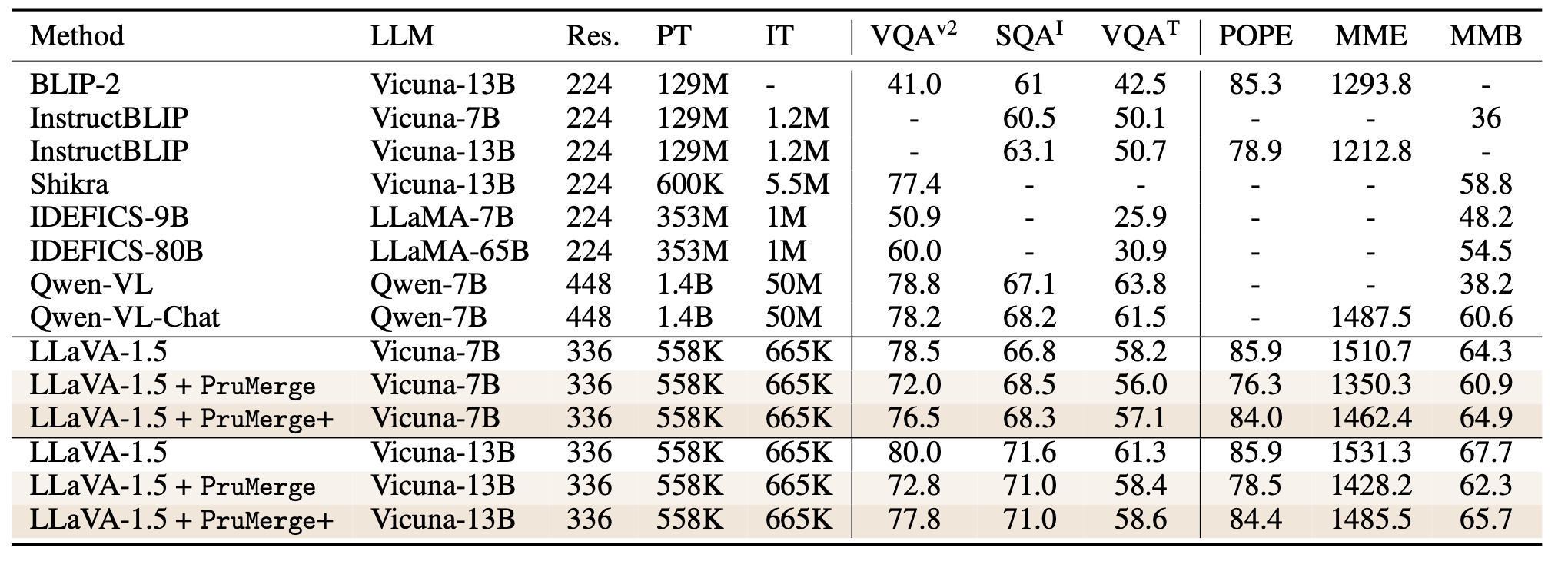
 We achieve comparable performance on LLaVA-1.5 benchmarks
We achieve comparable performance on LLaVA-1.5 benchmarks
 Our sampled tokens are better than naive visual token sampling
Our sampled tokens are better than naive visual token sampling
We compare sequential sampling and saptical sampling.
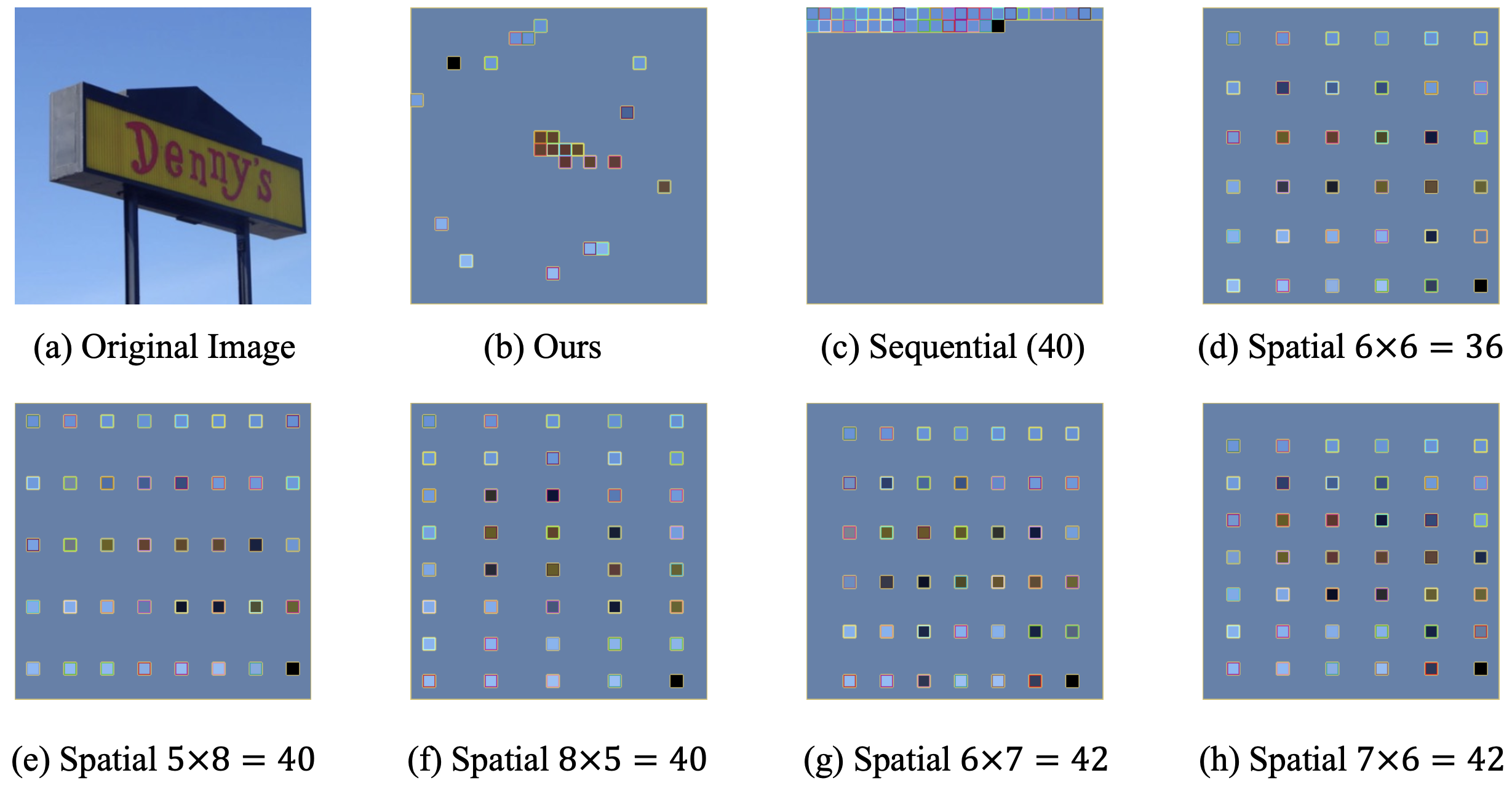
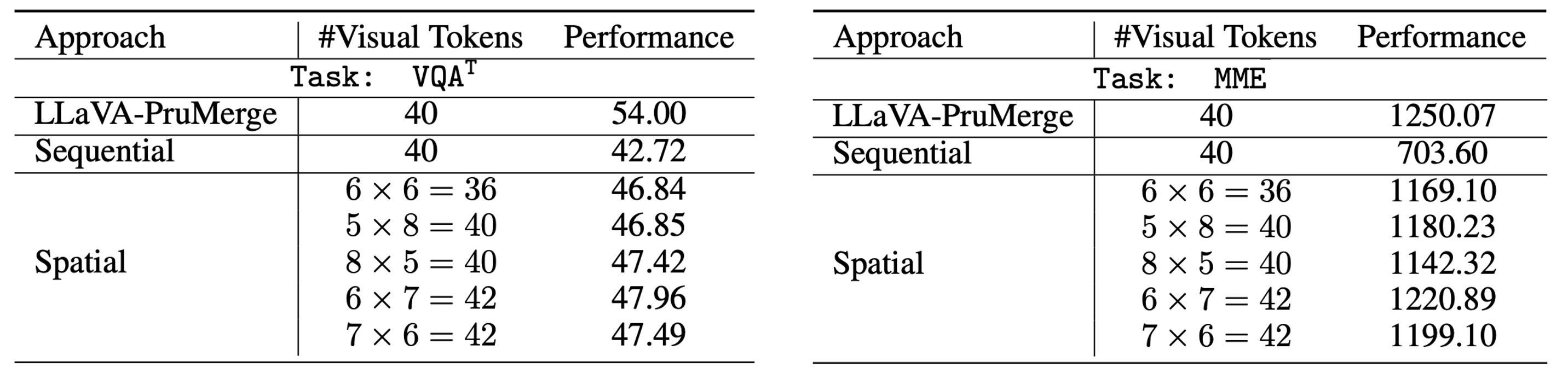
We receive better performance, especailly on tasks that requries detailed information, such as OCR.
BibTeX
@article{shang2024LLaVA-PruMerge,
title={LLaVA-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models},
author={Shang, Yuzhang and Cai, Mu and Xu, Bingxin and Lee, Yong Jae and Yan, Yan},
journal={ICCV},
year={2025}
}
Acknowledgement
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. We thank the LLaMA team for giving us access to their models, and open-source projects, including Alpaca and Vicuna.
Usage and License Notices: The data, code and checkpoint is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of CLIP, LLaMA, Vicuna and GPT-4. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.
Related Links: [CLIP] [LLaVA] [Instruction Tuning with GPT-4]